In Words, I Trust
trianita
This user hasn't shared any profile information
Posts by trianita
Laporan Project Aplikasi Sistem Multimedia
012 years
by trianita
in Uncategorized
Evermont Gift Shop
Latar Belakang
Sekarang ini banyak orang yang lebih memilih untuk belanja secara online karena lebih mudah untuk memilih. Maka dari itu kami membuat sebuah aplikasi untuk memudahkan masyarakat untuk belanja secara online yang kami beri nama Evermont Gift Shop. Kami menyediakan berbagai produk yang dapat dipilih customer dengan cara yang mudah dimengerti oleh customer.
ScreenShot Aplikasi

Ini adalah tampilan awal dari aplikasi kami. Ada logo dari online shop kami, ada juga tombol How to buy, Products, About Us, dan Contact Us.
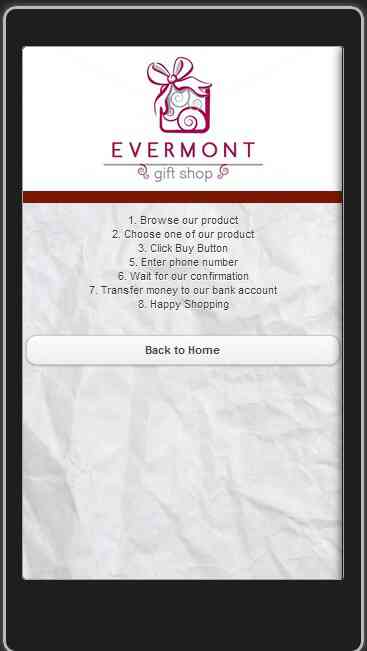
Jika customer menekan tombol “How to Buy” customer dapat tersambung ke bagian dimana kami memberi tahu bagaimana cara customer dapat memesan produk-produk yang kami tawarkan. Dan kami juga memberikan tombol ”Back to Home” yang dimana jika customer menekan tombol tersebut, customer dapat kembali ke tampilan awal dari aplikasi kami.
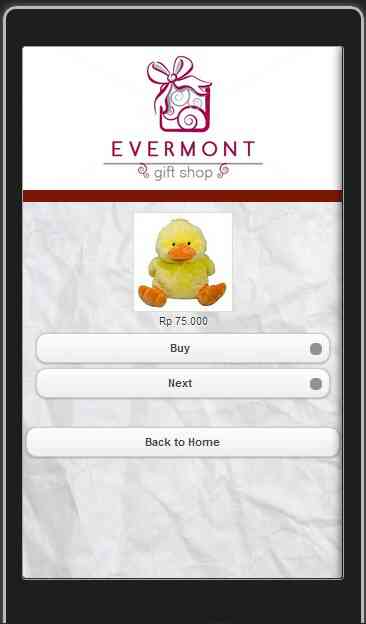
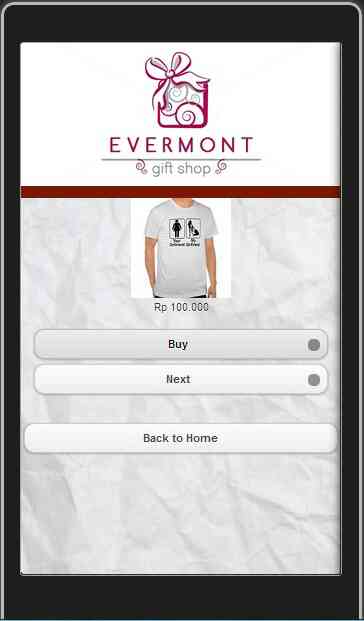
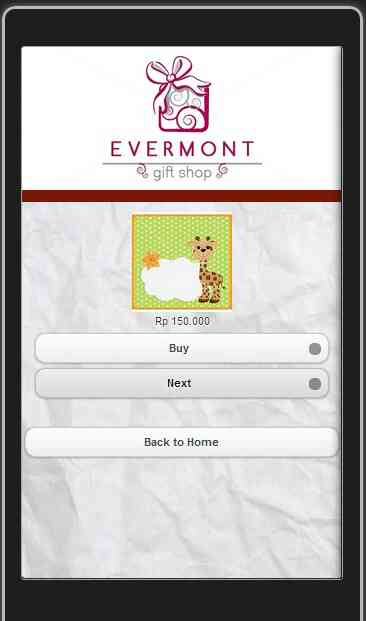
Jika customer menekan tombol “Products”, customer dapat melihat semua produk-produk dan harga yang kami tawarkan. Jika customer menekan tombol “Next”, customer dapat melihat produk selanjutnya. Dan jika customer sudah memilih produknya, customer dapat menekan tombol “Buy”t untuk ke step pembelian selanjutnya. Customer dapat kembali ke tampilan awal lagi dengan cara menekan tombol “Back to Home”.
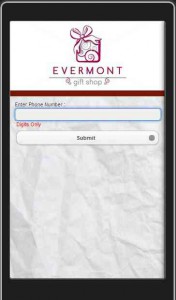
Ini adalah tampilan ketika customer menekan tombol “Buy” dari tampilan di atas, customer dapat tersambung ke bagian dimana customer harus mengisi nomor telefon untuk kami hubungi lebih lanjut. Jika customer sudah mengisi nomor telefon customer dapat menekan tombol “Submit”.

Ini adalah tampilan jika customer menekan tombol “About Us” customer dapat melihat video tentang persahabatan yang dimana customer bisa mempunyai ide untuk memberikan kado untuk orang-orang terdekat. Video ini juga memiliki kaitan yang erat dari aplikasi kami yaitu gift shop.

Jika customer ingin mengetahui tentang “Evermont Gift Shop” lebih lanjut customer dapat menekan tombol “Contact Us” yang memberikan informasi tentang Facebook dan Twitter dari Evermont Gift Shop.
TRIA NITA SITUMORANG (1601284384)
EVELINA LARISA (1601288331)
MONICA MARIA PRUDANCE (1601288722)
RAYMOND (1601223104)
Tugas OFF CLASS (GSLC) 31 Mei 2014
012 years
by trianita
in Uncategorized
1. TEXT CLASSIFICATION/TEXT CATEGORIZATION
Salah satu contoh pemanfaatan teks mining adalah text categorization yaitu proses pengelompokan dokumen, yang dalam tugas akhir ini adalah konten web page, ke dalam beberapa kelas yang telah ditentukan. Jika tidak ada overlap antar kelas, yaitu setiap dokumen hanya dikelompokan kedalam satu kelas maka text categorization ini disebut single label text categorization. Text categorization bertujuan untuk menemukan model dalam mengkategorisasikan teks natural language. Model tersebut akan digunakan untuk menentukan kelas dari suatu dokumen.
Beberapa metode text categorization yang sering dipakai antara lain : k- Nearest Neighbor, Naïve Bayes, Support Vektor Machine, Decision Tree, Neural Networks, Boosting. Dalam pengaplikasian text categorization terdapat beberapa tahap, yaitu : preprocessing, training phase dan testing phase.
- Preprocessing
Tahap pertama dalam text categorization adalah dokumen preprocessing adalah :
1. Ekstrasi Term
Ekstrasi term dilakukan untuk menentukan kumpulan term yang mendeskripsikan dokumen. Kumpulan dokumen di parsing untuk menghasilkan daftar term yang ada pada seluruh dokumen. Daftar term yang dihasilkan disaring dengan membuang tanda baca, angka, simbol dan stopwords. Dalam tugas akhir ini akan dibahas juga mengenai pengaruh stopwords removal terhadap hasil klasifikasi. Berikut ini merupakan penjelasan singkat mengenai stopwords.
Kebanyakan bahasa resmi di berbagai negara memiliki kata fungsi dan kata sambung seperti artikel dan preposisi yang hampir selalu muncul pada dokumen teks. Biasanya kata-kata ini tidak memiliki arti yang lebih di dalam memenuhi kebutuhan seorang searcher di dalam mencari informasi. Kata-kata tersebut (misalnya a, an, dan on pada bahasa Inggris) disebut sebagai Stopwords.
Sebuah sistem Text Retrieval biasanya disertai dengan sebuah Stoplist. Stoplist berisi sekumpulan kata yang ‘tidak relevan’, namun sering sekali muncul dalam sebuah dokumen. Dengan kata lain Stoplist berisi sekumpulan Stopwords.
Stopwords removal adalah sebuah proses untuk menghilangkan kata yang ‘tidak relevan’ pada hasil parsing sebuah dokumen teks dengan cara membandingkannya dengan Stoplist yang ada.
2. Seleksi Term
Jumlah term yang dihasilkan pada feature ekstrasi dapat menjadi suatu data yang berdimensi cukup besar. Karena dimensi dari ruang feature merupakan bag-of-words hasil pemisahan kata dari dokumennya. Untuk itu perlu dilakukan feature selection untuk mengurangi jumlah dimensi.
3. Representasi Dokumen
Supaya teks natural language dapat digunakan sebagai inputan untuk metode klasifikasi maka teks natural language diubah kedalam representasi vektor. Dokumen direpresentasikan sebagai vektor dari bobot term, dimana setiap term menggambarkan informasi khusus tentang suatu dokumen. Pembobotan dilakukan dengan melakukan perhitungan TFIDF. Term beserta bobotnya kemudian disusun dalam bentuk matrik.
- Training Phase
Tahap kedua dari text categorization adalah training. Pada tahap ini system akan membangun model yang berfungsi untuk menentukan kelas dari dokumen yang belum diketahui kelasnya. Tahap ini menggunakan data yang telah diketahui kelasnya (data training) yang kemudian akan dibentuk model yang direpresantasikan melalui data statistik berupa mean dan standar deviasi masing-masing term pada setiap kelas.
- Testing Phase
Tahap terakhir adalah tahap pengujian yang akan memberikan kelas pada data testing dengan menggunakan model yang telah dibangun pada tahap training. Tujuan dilakukan testing adalah untuk mengetahui performansi dari model yang telah dibentuk. Dengan beberapa parameter pengukuran yaitu akurasi, precision, recall, dan f-measure.
- Pembobotan
Vector space model merepresentasikan dokumen dengan term yang memiliki bobot. Bobot tersebut menyatakan kepentingan/kontribusi term terhadap suatu dokumen dan kumpulan dokumen. Kepentingan suatu kata dalam dokumen dapat dilihat dari frekuensi kemunculannya terhadap dokumen. Biasanya term yang berbeda memiliki frekuensi yang berbeda. Dibawah ini terdapat beberapa metode pembobotan :
1. Term Frequency
Term frequency merupakan metode yang paling sederhana dalam membobotkan setiap term. Setiap term diasumsikan memiliki kepentingan yang proporsional terhadap jumlah kemunculan term pada dokumen. Bobot dari term t pada dokumen d yaitu :
TF(d,t) = f (d, t)
Dimana f(d,t) adalah frekuensi kemunculan term t pada dokumen d.
2. Inverse Document Frequency (IDF)
Bila term frequency memperhatiakan kemunculan term didalam dokumen, maka IDF memperhatikan kemunculan term pada kumpulan dokumen. Latar belakang pembobotan ini adalah term yang jarang muncul pada kumpulan dokumen sangat bernilai. Kepentingan tiap term diasumsikan memilki proporsi yang berkebalikan dengan jumlah dokumen yang mengandung term. Faktor IDF dari term t yaitu :
IDF(t) = log( n / df(t) )
Dimana N adalah jumlah seluruh dokumen, df(t) jumlah dokumen yang mengandung term t.
3. TFIDF
Perkalian antara term frequency dan IDF dapat menghasilkan performansi yang lebih baik. Kombinasi bobot dari term t pada dokumen d yaitu :
TDIF(d,t) = TF(d,t) x IDF(t)
Term yang sering muncul pada dokumen tapi jarang muncul pada kumpulan dokumen memberikan nilai bobot yang tinggi. TFIDF akan meningkat dengan jumlah kemunculan term pada dokumen dan berkurang dengan jumlah term yang muncul pada dokumen.
2. INFORMATION RETRIEVAL
“Information Retrieval adalah studi tentang sistem pengindeksan, pencarian, dan mengingat data, khususnya teks atau bentuk tidak terstruktur lainnya.”
[virtechseo.com]
“Information Retrieval adalah seni dan ilmu mencari informasi dalam dokumen, mencari dokumen itu sendiri, mencari metadata yang menjelaskan dokumen, atau mencari dalam database, apakah relasional database itu berdiri sendiri atau database hypertext jaringan seperti Internet atau intranet, untuk teks , suara, gambar, atau data “
[Wikipedia]
Information Retrieval adalah “bidang di persimpangan ilmu informasi dan ilmu komputer. Berkutat dengan pengindeksan dan pengambilan informasi dari sumber informasi heterogen dan sebagian besar-tekstual. Istilah ini diciptakan oleh Mooers pada tahun 1951, yang menganjurkan bahwa diterapkan ke “aspek intelektual” deskripsi informasi dan sistem untuk pencarian (Mooers, 1951). “
[Hersh, 2003]
3. HITS ALGHORITM
Algoritma Hyperlink Induced Topic Search (HITS) Kleinberg memberikan gagasan baru tentang hubungan antara hubs dan authorities. Dalam algoritma HITS, setiap simpul (situs) p
diberi bobot hub (xp) dan bobot authority (yp)
melalui operasi
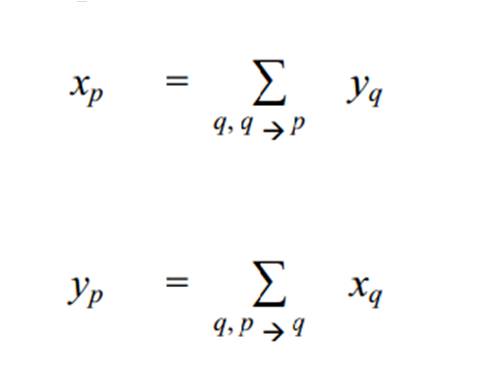
yang dalam hal ini nilai xp diperoleh dari jumlah seluruh nilai yq di mana q adalah situs-situs yang menunjuk (mengandung hyperlink) ke situs p (notasi q p menunjukkan bahwa q menunjuk ke p). Sementara nilai yp diperoleh dari jumlah seluruh nilai xq. Dari operasi tersebut, dapat dilihat bahwa antara hubs dan authorities terdapat sebuah hubungan yang saling memperkuat satu sama lain, yaitu: sebuah hub yang bagus menunjuk ke banyak authorities yang juga bagus, sementara sebuah authority yang bagus ditunjuk oleh banyak hubs yang juga bagus.
Untuk melakukan update secara berkala dari nilai-nilai tersebut, terdapat cara yang lebih
singkat dibanding dengan melakukan perhitungan ulang dari rumus yang telah dibahas sebelumnya. Pertama-tama, nomori situs-situs hasil pencarian dengan angka {1,2,…,n} dan tentukan matriks ketetanggaan A yang berukuran n x n dari situs-situs tersebut. Lalu, himpun
seluruh nilai x dalam sebuah vektor x = (x1,x2,…,xn) , lakukan hal yang serupa pada seluruh nilai y. Selanjutnya, update nilai x dan y dapat dilakukan melalui operasi
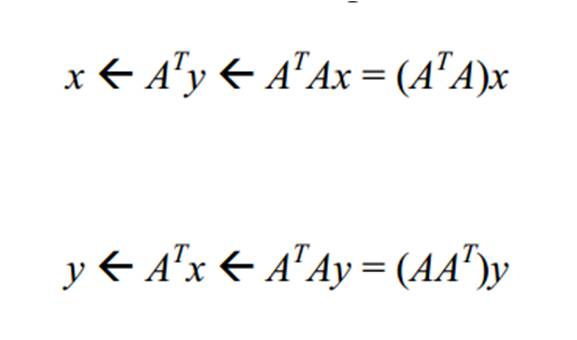
Di bawah ini adalah gambaran keseluruhan dari algoritma HITS.

Pada akhirnya, algoritma HITS ini menghasilkan sebuah daftar singkat yang terdiri dari situs-situs dengan bobot hub terbesar serta situs-situs dengan bobot authority terbesar. Yang menarik dari algoritma HITS adalah: setelah memanfaatkan kata kunci (topik yang dicari) untuk membuat himpunan akar (root) R, algoritma ini selanjutnya sama sekali tidak mempedulikan isi tekstual dari situs-situs hasil pencarian tersebut. Dengan kata lain, HITS murni merupakan sebuah algoritma berbasis link setelah himpunan akar terbentuk. Walaupun demikian, secara mengejutkan HITS memberikan hasil pencarian yang baik untuk banyak kata kunci. Sebagai contoh, ketika dites dengan kata kunci ”search engine”, lima authorities terbaik yang dihasilkan oleh algoritma HITS adalah Yahoo!, Lycos, AltaVista, Magellan, dan Excite − padahal tidak satupun dari situs-situs tersebut mengandung kata ”search engine”.
4. PROLOG
Sejarah Prolog
Prolog merupakan singkatan dari “Programing In Logic” pertama kali dikembangkan oleh Alain Colmetrouer dan P.Roussel di Universitas Marseilles Prancis tahun 1972. Selama tahun 70an, prolog populer di Eropa untuk aplikasi AI. Sedangkan di Amerika Serikat, para peneliti juga mengembangkan bahasa lain untuk aplikasi yang sama yaitu LISP. LISP mempunyai kelebihan dibandingkan prolog , tetapi LISP lebih sulit dipelajari.
Pada awalnya, Prolog dan LISP sangat lambat dalam eksekusi program dan memakan memori yang besar sehingga hanya kalangan tertentu yang menggunakannya. Dengan adanya Compiler Prolog, kecepatan eksekusi program dapat ditingkatkan, namun Prolog masih dipandang sebagai bahasa yang terbatas (hanya digunakan di kalangan perguruan tinggi dan riset).
Pandangan tersebut tiba-tiba berubah di tahun 1981 pada konverensi internasional I dalam sistem generasi kelima di Tokyo, Jepang. Jepang yang saat itu mengalami kesulitan bersaing dalam pemasaran komputer dengan Amerika Serikat, mencanangkan rencana pengembangan teknologi hardware dan software untuk tahun 1990an. Dan bahasa yang dipilih adalah Prolog.
Sejak saat itu, banyak orang menaruh minat pada prolog dan saat itu telah dikembangkan versi prolog yang mempunyai kecepatan dan kemampuan yang lebih tinggi, lebih murah dan lebih mudah digunakan, baik untuk komputer mainframe maupun komputer pribadi sehingga Prolog menjadi alat yang penting dalam program aplikasi kecerdasan buatan (AI) dan pengembangan sistem pakar (expert sistem).
Perbedaan Prolog dengan Bahasa Pemrograman Lainnya
Hampir semua bahasa pemrograman yang ada pada saat ini seperti Pascal, C, Fortran, disebutprocedural language untuk menggunakan bahasa tersebut diperlukan algoritma atau prosedur yang dibuat untuk menyelesaikan masalah. Program dapat menjalankan prosedur yang sama berulang-ulang dengan data masukkan yang berbeda-beda. Prosedur serta pengendalian program sepenuhnya ditentukan oleh programmer dan perhitungan yang dilakukan sesuai dengan prosedur yang telah dibuat. Dengan kata lain, Pemrograman harus memberi tahu komputer bagaimana komputer harus menyelesaikan masalah.
Prolog mempunyai sifat-sifat yang berbeda dengan bahasa yang disebutkan diatas, prolog disebut sebagai object oriented language atau declarative language. Dalam prolog tidak terdapat prosedur, tapi hanya tampilan data-data object (fakta) yang akan diolah dengan relasi antar object tersebut yang membentuk suatu aturan. Aturan-aturan ini disebut heuristik dan diperlukan dalam mencari suatu jawaban, dengan kata lain, prolog dalam prolog adalah database.
Pemrogram menentukan tujuan (Goal) dan komputer akan menentukan bagaimana cara mencapai tujuan tersebut serta mencari jawabannya. Caranya dengan menggunakan “Formal Reasoning” yaitu membuktikan cocok tidaknya tujuan dengan data-data yang telah ada dan relasinya. Prolog memecahkan masalah seperti yang dilakukan oleh pikiran manusia.
Dengan demikian, Prolog sangat ideal untuk memecahkan masalah yang tidak terstruktur dan yang procedure pemecahannya tidak diketahui, khusunya untuk memecahkan masalah non numeric.
Keampuhan Prolog
Terletak pada kemampuannya dalam mengambil kesimpulan (jawaban) dari data-data yang ada. Karena program dalam bahasa prolog tidak memerlukan prosedur (algoritma). Prolog sangat ideal untuk memecahkan masalah yang tidak terstruktur dan yang prosedur pemecahannya tidak diketahui, khususnya untuk memecahkan masalah non numerik.
Misalnya, dalam pembuatan program catur dengan prolog untuk menentukkan gerakan catur anda tidak perlu menganalisis semua kemungkinan atau menentukkan suatu prosedur tertentu untuk untuk menentukan gerakan berikutnya. Tetapi anda cukup menuliskan aturan umum permainan catur dan lebih baik lagi jika ditambah dengan aturan yang diperoleh dari pengalaman. Prolog akan menentukan sendiri langkah yang akan diambil berdasarkan data-data yang ada saat itu dan aturan-aturan yang diberikan.
Aplikasi Prolog
Prolog digunakan khususnya dibidang kecerdasan buatan (Artificial Intelegent) meliputi bidang:
1. Sistem Pakar (Expert System)
adalah program yang menggunakan teknik pengambilan kesimpulan dari data-data yang didapat seperti yang dilakukan oleh seorang ahli dalam memecahkan masalah. sebagai contoh program mendiagnosa penyakit. Pemakai menentukan tujuan (goal) yaitu penyakit yang diderita, untuk mendapatkan jawaban, program akan memberi pertanyaan yang harus dijawab oleh pemakai program.
2. Pengolahan bahasa alami (Natural Language Processing)
Natural Language Processing adalah program yang dibuat agar pemakai dapat berkomunikasi dengan komputer dalam bahasa manusia sehari-hari. Sebagai contoh adalah Lotus HAL, yaitu program Bantu untuk Lotus 1-2-3 agar dapat menerima perintah bahasa inggris seperti bahasa biasa. Program pengolahan bahasa alami menggunakan teknik AI dalam analisis input bahasa yang dimasukan melalui keyboard, program tersebut berusaha mengidentifikasi sintak, semantik dan konteks yang terkandung dalam suatu kalimat agar bisa sampai pada kesimpulan untuk bisa memberikan jawaban.
3. Robotik
Dalam robotik, Prolog digunakan untuk mengolah data masukan yang berasal dari sensor dan mengambil keputusan untuk menentukan gerakan yang harus dilakukan. Apalagi kalau robot menemukan peristiwa yang tidak diharapkan atau situasi yang berbeda.
4. Pengenalan Pola (Pattern Recognition)
Pengenalan pola banyak diterapkan dalam bidang robotik dan pengolahan citra (image processing). Misalkan, bagaimana komputer dapat membedakan gambar sebuah benda dan gambar benda yang lain, atau sebuah obyek yang berada diatas obyek lain.
Tugas OFF CLASS (GSLC) 8 Mei 2014
012 years
by trianita
in Uncategorized
1. Apa yang dimaksud supervised learning, unsupervised learning, dan reinforcement learning? Berikan contoh masing-masing!
SUPERVISED LEARNING
Supervised learning merupakan suatu pembelajaran yang terawasi dimana jika output yang diharapkan telah diketahui sebelumnya. Biasanya pembelajaran ini dilakukan dengan menggunakan data yang telah ada. Pada metode ini, setiap pola yang diberikan kedalam jaringan saraf tiruan telah diketahui outputnya. Satu pola input akan diberikan ke satu neuron pada lapisan input. Pola ini akan dirambatkan di sepanjang jaringan syaraf hingga sampai ke neuron pada lapisan output. Lapisan output ini akan membangkitkan pola output yang nantinya akan dicocokkan dengan pola output targetnya. Apabila terjadi perbedaan antara pola output hasil pembelajaran dengan pola output target, maka akan muncul error. Dan apabila nilai error ini masih cukup besar, itu berarti masih perlu dilakukan pembelajaran yang lebih lanjut.
Contoh algoritma jaringan saraf tiruan yang mernggunakan metode supervised learning adalah hebbian (hebb rule), perceptron, adaline, boltzman, hapfield, dan backpropagation.
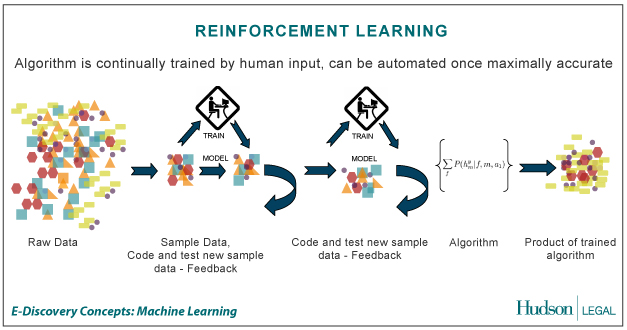
UNSUPERVISED LEARNING
Unsupervised learning merupakan pembelajaran yang tidak terawasi yang tidak memerlukan target output. Pada metode ini tidak dapat ditentukan hasil seperti apa yang diharapkan selama proses pembelajaran. Nilai bobot yang disusun dalam proses range tertentu tergantung pada nilai output yang diberikan. Tujuan metode uinsupervised learning ini agar kita dapat mengelompokkan unit-unit yang hampir sama dalam satu area tertentu. Pembelajaran ini biasanya sangat cocok untuk klasifikasi pola.
Contoh algoritma jaringan saraf tiruan yang menggunakan metode unsupervised ini adalah competitive, hebbian, kohonen, LVQ(Learning Vector Quantization), neocognitron.
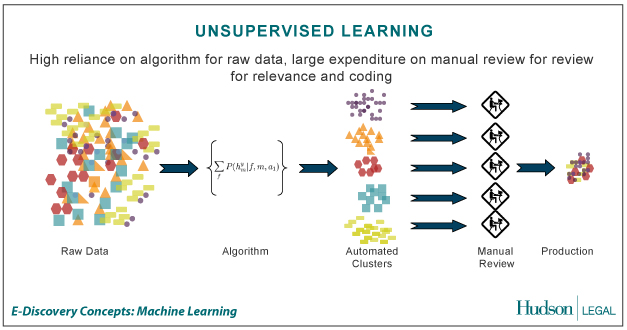
REINFORCEMENT LEARNING
Reinforcement Learning adalah salah satu paradigma baru di dalam learning theory. RL dibangun dari proses mapping (pemetaan) dari situasi yang ada di environment (states) ke bentuk aksi (behavior) agar dapat memaksimalkan reward. Agent yang bertindak sebagai sang learner tidak perlu diberitahukan behavior apakah yang akan sepatutnya dilakukan, atau dengan kata lain, biarlah sang learner belajar sendiri dari pengalamannya. Ketika ia melakukan sesuatu yang benar berdasarkan rule yang kita
tentukan, ia akan mendapatkan reward, dan begitu juga sebaliknya.
RL secara umum terdiri dari 4 komponen dasar, yaitu :
1. Policy : kebijaksanaan
2. Reward function
3. Value function
4. Model of environment
Policy adalah fungsi untuk membuat keputusan dari agent yang menspesifikasikan tindakan apakah yang mungkin dilakukan dalam berbagai situasi yang ia jumpai. Policy inilah yang bertugas memetakan perceived states ke dalam bentuk aksi. Policy bisa berupa fungsi sederhana, atau lookup table. Policy ini merupakan inti dari RL yang sangat menentukan behavior dari suatu agent.
Reward function mendefinisikan tujuan dari kasus atau problem yang dihadapi. Ia mendefinisikan reward and punishment yang diterima agent saat ia berinteraksi dengan environment. Tujuan utama dari rewar d function ini adalah memaksimalkan total reward pada kurun waktu tertentu setelah agent itu berinteraksi.
Value function menspesifikasikan fungsi akumulasi dari total reward yang didapatkan oleh agent. Jika reward function berbicara pada masing-masing partial time dari proses interaksi, value function berbicara pada long-term dari proses interaksi.
Model of environment adalah sesuatu yang menggambarkan behavior dari environment. Model of environment ini sangat berguna untuk mendesain dan merencanakan behavior yang tepat pada situasi mendatang yang memungkinkan sebelum agent sendiri mempunyai pengalaman dengan situasi itu. Saat masa-masa awal RL dikembangkan, model of environment yang ada berupa trial and error. Namun modern RL sekarang sudah mulai menjajaki spektrum dari low -level, trial and error menuju high-level, deliberative planning.
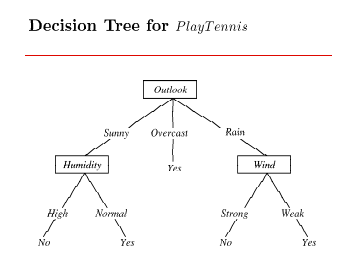
2. Apa yang dimaksud dengan Learning Decision Tree dan berikan contohnya!
LEARNING DECISION TREE
Decision tree merepresentasikan sebuah tree dimana internal nodenya mengetes sebuah atribut, masing- masing cabangnya berhubungan dengan nilai dari atribut dan masing- masing lead nodenya berisi sebuah klasifikasi. Algoritma ini merupakan salah satu dari teknik yang paling efisien dan populer dalam machine learning.
Kelebihan dari decision tree adalah apabila ukurannya tidak terlalu besar, tree ini akan dapat dengan mudah dimengerti oleh manusia. Hal ini akan sangat berguna karena manusia dapat memahami cara kerjanya. Sebagai tambahan, apabila data yang ada sangat besar, maka decision tree akan bekerja lebih cepat daripada version space.
TUGAS VIDEO SISTEM MULTIMEDIA
012 years
by trianita
in Uncategorized
COUNT ON ME (STOP MOTION)
Video yang mengandung lagu dan foto yang di padukan menjadi satu kesatuan, merupakan hal yang baru saja booming pada dunia anak muda, seperti untuk membuat video anniversary, video ulangtahun, dan masih banyak lagi. Dimana yang sering kita sebut stop motion. Awalnya stopmotion hanyalah di buat dalam pembuatan animasi, dan ya, stopmotion merupakan suatu teknik animasi untuk membuat objek yang di manipulasikan secara fisik agar terlihat bergerak dengan sendirinya. bahkan sekarang stopmotion sudah banyak variasi baru, dengan menambahkan video, dan beberapa hal unik lainnya.
Dan kami menyediakan sebuah stopmotion dengan mengangkat tema utama “PERSAHABATAN”, yang dilatar belakangi dengan lagu yang diciptakan dan dinyanyikan oleh Bruno Mars berjudul “Count On Me” yang baru saja rilis pada tahun 2010 lalu. Kami memilih lagu ini, karena arti dari lirik itu sendiri sangatlah menyentuh hati, bahkan dari arti lagu tersebut kita dapat mempelajari itulah arti dari sahabat, itulah sahabat yang seharusnya. Dan kami memilih tema persahabatan, karena persahabatan tidak ada batas umur maupun waktu, bahkan persahabatan tidak hanya dengan teman, tapi juga dengan Tuhan, orang tua, bahkan pasangan hidup pun dapat menjadi sahabat. dan kami memilih lirik lagu sebagai kumpulan foto di dalam nya, karena dengan membaca sebuah lirik lagu, setiap orang dapat lebih mudah mengerti apa makna dari lagu itu, daripada sudah hafal dan menyanyikannya.
Tidak ada arti pasti dari sahabat, sahabat ada saat kita menganggapnya lebih dari temanmu yang lain. Sahabat adalah seorang teman dimana kita dapat dengan leganya mengeluarkan apa yang ada di dalam pikiranmu bahkan hatimu, akankah itu senang atau sedih. Teman yang selalu ada saat kita butuh, teman yang ada ketika kita jatuh dan bahkan bangkit bersama. Teman yang benar benar peduli. Bahkan tanpa disadari sebagian hidupmu habis hanya dengan mereka, tersenyum, bercanda, tertawa, bahkan menangis bersama.
Sebelum anda memutarkan video yang kami sediakan, mari ajak sahabatmu bernyanyi bersama, tersenyum bersama, dan menyadari bersama, bahwa seseorang yang kamu ajak adalah seseorang yang sangat berarti bagi mu. Selamat menikmati keindahan persahabat, sebelum batu kecil merenggangkan kalian, bahkan waktu, tempat, ataupun kesibukan menjauhkan kalian. Dan ada satu masa kamu akan merasa sangat kehilangan.
Storyboard


Link video : Count on Me Stop Motion 
Anggota Kelompok 2 :
TRIA NITA SITUMORANG (1601284384)
EVELINA LARISA (1601288331)
MONICA MARIA PRUDANCE (1601288722)
RAYMOND (1601223104)
Tugas OFF CLASS (GSLC) 13 Maret 2014
012 years
by trianita
in Uncategorized
1. Apa yang dimaksud Adversarial Search & Constraint Satisfaction Problems? Berikan contoh!
Adversarial search adalah suatu pencarian dengan mencari berbagai kemungkinan atau solusi yang akan terjadi pada suatu masalah.
Contoh : catur, tic-tac-toe, othello.
Constraint Satisfaction Problems adalah suatu masalah yang diselesaikan dengan metode pencarian yang paling sesuai dengan keinginan oleh user dengan cara memberikan berbagai alternatif pilihan.
Contoh : cryptarithmetic, map coloring, backtracking search, forward checking.
2. Apa itu Propositional Logic? Berikan contoh!
Propositional logic merupakan salah satu bentuk (bahasa) representasi logika yang paling tua dan paling sederhana yang dapat menggambarkan dan memanipulasi fakta dengan menggunakan aturan-aturan aljabar Boolean
Propositional logic membentuk statement sederhana atau statement yang kompleks dengan menggunakan propositional connec-tive, dimana mekanisme ini menentukan kebenaran dari sebuah statement kompleks dari nilai kebenaran yang direpresentasikan oleh statement lain yang lebih sederhana.
Contoh :
– Paris adalah ibukota dari negara Perancis dan Paris mempunyai populasi lebih dari 2 juta jiwa.
– 2 + 2 = 4
3. Buat coding (Boleh C, C++ atau Java) untuk Algoritma A & Algoritma A* (A Star)!
a. Algoritma A
class Graph
{
protected $_len = 0;
protected $_g = array();
protected $_visited = array();
public function __construct()
{
$this->_g = array(
array(0, 2, 0, 0, 5, 1),
array(1, 0, 3, 0, 0, 0),
array(0, 2, 0, 8, 0, 0),
array(0, 0, 3, 0, 5, 0),
array(1, 0, 0, 8, 0, 1),
array(1, 0, 0, 0, 5, 0),
);
$this->_len = count($this->_g);
$this->_initVisited();
}
protected function _initVisited()
{
for ($i = 0; $i < $this->_len; $i++) {
$this->_visited[$i] = 0;
}
}
public function bestFirst($vertex)
{
$this->_visited[$vertex] = 1;
echo $vertex . “\n“;
asort($this->_g[$vertex]);
foreach ($this->_g[$vertex] as $key => $v) {
if ($v > 0 && !$this->_visited[$key]) {
$this->bestFirst($key);
}
}
}
}
$g = new Graph();
// 2 1 0 5 4 3
$g->bestFirst(2);
Algoritma A*
#include <iostream>
#include <iomanip>
#include <queue>
#include <string>
#include <math.h>
#include <ctime>
using namespace std;
const int n=60; // horizontal size of the map
const int m=60; // vertical size size of the map
static int map[n][m];
static int closed_nodes_map[n][m]; // map of closed (tried-out) nodes
static int open_nodes_map[n][m]; // map of open (not-yet-tried) nodes
static int dir_map[n][m]; // map of directions
const int dir=8; // number of possible directions to go at any position
// if dir==4
//static int dx[dir]={1, 0, -1, 0};
//static int dy[dir]={0, 1, 0, -1};
// if dir==8
static int dx[dir]={1, 1, 0, -1, -1, -1, 0, 1};
static int dy[dir]={0, 1, 1, 1, 0, -1, -1, -1};
class node
{
// current position
int xPos;
int yPos;
// total distance already travelled to reach the node
int level;
// priority=level+remaining distance estimate
int priority; // smaller: higher priority
public:
node(int xp, int yp, int d, int p)
{xPos=xp; yPos=yp; level=d; priority=p;}
int getxPos() const {return xPos;}
int getyPos() const {return yPos;}
int getLevel() const {return level;}
int getPriority() const {return priority;}
void updatePriority(const int & xDest, const int & yDest)
{
priority=level+estimate(xDest, yDest)*10; //A*
}
// give better priority to going strait instead of diagonally
void nextLevel(const int & i) // i: direction
{
level+=(dir==8?(i%2==0?10:14):10);
}
// Estimation function for the remaining distance to the goal.
const int & estimate(const int & xDest, const int & yDest) const
{
static int xd, yd, d;
xd=xDest-xPos;
yd=yDest-yPos;
// Euclidian Distance
d=static_cast<int>(sqrt(xd*xd+yd*yd));
// Manhattan distance
//d=abs(xd)+abs(yd);
// Chebyshev distance
//d=max(abs(xd), abs(yd));
return(d);
}
};
// Determine priority (in the priority queue)
bool operator<(const node & a, const node & b)
{
return a.getPriority() > b.getPriority();
}
// A-star algorithm.
// The route returned is a string of direction digits.
string pathFind( const int & xStart, const int & yStart,
const int & xFinish, const int & yFinish )
{
static priority_queue<node> pq[2]; // list of open (not-yet-tried) nodes
static int pqi; // pq index
static node* n0;
static node* m0;
static int i, j, x, y, xdx, ydy;
static char c;
pqi=0;
// reset the node maps
for(y=0;y<m;y++)
{
for(x=0;x<n;x++)
{
closed_nodes_map[x][y]=0;
open_nodes_map[x][y]=0;
}
}
// create the start node and push into list of open nodes
n0=new node(xStart, yStart, 0, 0);
n0->updatePriority(xFinish, yFinish);
pq[pqi].push(*n0);
open_nodes_map[x][y]=n0->getPriority(); // mark it on the open nodes map
// A* search
while(!pq[pqi].empty())
{
// get the current node w/ the highest priority
// from the list of open nodes
n0=new node( pq[pqi].top().getxPos(), pq[pqi].top().getyPos(),
pq[pqi].top().getLevel(), pq[pqi].top().getPriority());
x=n0->getxPos(); y=n0->getyPos();
pq[pqi].pop(); // remove the node from the open list
open_nodes_map[x][y]=0;
// mark it on the closed nodes map
closed_nodes_map[x][y]=1;
// quit searching when the goal state is reached
//if((*n0).estimate(xFinish, yFinish) == 0)
if(x==xFinish && y==yFinish)
{
// generate the path from finish to start
// by following the directions
string path=””;
while(!(x==xStart && y==yStart))
{
j=dir_map[x][y];
c=’0’+(j+dir/2)%dir;
path=c+path;
x+=dx[j];
y+=dy[j];
}
// garbage collection
delete n0;
// empty the leftover nodes
while(!pq[pqi].empty()) pq[pqi].pop();
return path;
}
// generate moves (child nodes) in all possible directions
for(i=0;i<dir;i++)
{
xdx=x+dx[i]; ydy=y+dy[i];
if(!(xdx<0 || xdx>n-1 || ydy<0 || ydy>m-1 || map[xdx][ydy]==1
|| closed_nodes_map[xdx][ydy]==1))
{
// generate a child node
m0=new node( xdx, ydy, n0->getLevel(),
n0->getPriority());
m0->nextLevel(i);
m0->updatePriority(xFinish, yFinish);
// if it is not in the open list then add into that
if(open_nodes_map[xdx][ydy]==0)
{
open_nodes_map[xdx][ydy]=m0->getPriority();
pq[pqi].push(*m0);
// mark its parent node direction
dir_map[xdx][ydy]=(i+dir/2)%dir;
}
else if(open_nodes_map[xdx][ydy]>m0->getPriority())
{
// update the priority info
open_nodes_map[xdx][ydy]=m0->getPriority();
// update the parent direction info
dir_map[xdx][ydy]=(i+dir/2)%dir;
// replace the node
// by emptying one pq to the other one
// except the node to be replaced will be ignored
// and the new node will be pushed in instead
while(!(pq[pqi].top().getxPos()==xdx &&
pq[pqi].top().getyPos()==ydy))
{
pq[1-pqi].push(pq[pqi].top());
pq[pqi].pop();
}
pq[pqi].pop(); // remove the wanted node
// empty the larger size pq to the smaller one
if(pq[pqi].size()>pq[1-pqi].size()) pqi=1-pqi;
while(!pq[pqi].empty())
{
pq[1-pqi].push(pq[pqi].top());
pq[pqi].pop();
}
pqi=1-pqi;
pq[pqi].push(*m0); // add the better node instead
}
else delete m0; // garbage collection
}
}
delete n0; // garbage collection
}
return “”; // no route found
}
int main()
{
srand(time(NULL));
// create empty map
for(int y=0;y<m;y++)
{
for(int x=0;x<n;x++) map[x][y]=0;
}
// fillout the map matrix with a ‘+’ pattern
for(int x=n/8;x<n*7/8;x++)
{
map[x][m/2]=1;
}
for(int y=m/8;y<m*7/8;y++)
{
map[n/2][y]=1;
}
// randomly select start and finish locations
int xA, yA, xB, yB;
switch(rand()%8)
{
case 0: xA=0;yA=0;xB=n-1;yB=m-1; break;
case 1: xA=0;yA=m-1;xB=n-1;yB=0; break;
case 2: xA=n/2-1;yA=m/2-1;xB=n/2+1;yB=m/2+1; break;
case 3: xA=n/2-1;yA=m/2+1;xB=n/2+1;yB=m/2-1; break;
case 4: xA=n/2-1;yA=0;xB=n/2+1;yB=m-1; break;
case 5: xA=n/2+1;yA=m-1;xB=n/2-1;yB=0; break;
case 6: xA=0;yA=m/2-1;xB=n-1;yB=m/2+1; break;
case 7: xA=n-1;yA=m/2+1;xB=0;yB=m/2-1; break;
}
cout<<“Map Size (X,Y): “<<n<<“,”<<m<<endl;
cout<<“Start: “<<xA<<“,”<<yA<<endl;
cout<<“Finish: “<<xB<<“,”<<yB<<endl;
// get the route
clock_t start = clock();
string route=pathFind(xA, yA, xB, yB);
if(route==””) cout<<“An empty route generated!”<<endl;
clock_t end = clock();
double time_elapsed = double(end – start);
cout<<“Time to calculate the route (ms): “<<time_elapsed<<endl;
cout<<“Route:”<<endl;
cout<<route<<endl<<endl;
// follow the route on the map and display it
if(route.length()>0)
{
int j; char c;
int x=xA;
int y=yA;
map[x][y]=2;
for(int i=0;i<route.length();i++)
{
c =route.at(i);
j=atoi(&c);
x=x+dx[j];
y=y+dy[j];
map[x][y]=3;
}
map[x][y]=4;
// display the map with the route
for(int y=0;y<m;y++)
{
for(int x=0;x<n;x++)
if(map[x][y]==0)
cout<<“.”;
else if(map[x][y]==1)
cout<<“O”; //obstacle
else if(map[x][y]==2)
cout<<“S”; //start
else if(map[x][y]==3)
cout<<“R”; //route
else if(map[x][y]==4)
cout<<“F”; //finish
cout<<endl;
}
}
getchar(); // wait for a (Enter) keypress
return(0);
}
Basa Basi dari Manusia Seksi
012 years
by trianita
in Uncategorized
Hai! Halo! Huy! Aloha! Chihuaha!
Hehehehehehehehehehe.
Jadi ceritanya saya bikin blog lagi nih. Pertama kali punya blog, saya lagi lucu-lucunya pakai seragam putih-biru. Pertama kali jatuh cinta juga sama. Waktu pakai seragam putih-biru juga. Hehe. Ini blog formal ya? Hehe. Maaf Pak Dosen dan Bu Dosen. Hehe.
Lanjut lagi… Saya sempat punya blog yang isinya tuh… HMM… BEEEH… GILAAA…. ISINYA TUH… Standar. Tentang masa-masa SMP yang begitu membahagiakan, tentang kelabilan saya, tentang aku-kamu-dia-kita-mereka, tentang goreng, “tentang-tentang dia kaya dia bisa seenaknya aja gitu? HELLOW?!”, “PAK ABSEN SAYA BELUM DITENTANG PAK! YANG NOMER TIGA PAK. IYA YANG ITU PAK! MAKASIH PAK!”. Uhuk uhuk. Maap, keselek.
Tapi, saya bangga banget punya blog itu. Soalnya ngehitz getoh dulu. Ya getoh… Gueh jadi merasa sebagai anggota anak gaol yang punya blog getoh. Uhuk uhuk. Maap, keselek lagi.
Saya sempat ngehapus blog saya, terus saya bikin lagi. Hapus , bikin lagi. Hapus, bikin lagi. Hapus, bikin lagi. Samalah kayak waktu saya sama dia. Udah putus, eh balikan lagi. Putus, balikan lagi. Putus… EH NGGAK BALIKAN LAGI. God, help me through all this. :'(
Pokoknya…
Selamat datang di Binusian Blog ya, Tria Nita Situmorang.
Iya. Makasih ya Tria Nita Situmorang.
Sama-sama. Hehe.
Hehe.
*percakapan dengan diri sendiri*
WOOHOOO! WELCOME TO MY BLOG! *sebar confetti*
Oh iya, dapat quotes dari Mas Anang di Jember.

“AKU SIH NO”
P.S: The real reason why I keep making blog/Why I keep writing is… because I’m better in writing than talking. :p
Hello world!
112 years
by trianita
in Uncategorized
Welcome to Binusian blog.
This is the first post of any blog.binusian.org member blog. Edit or delete it, then start blogging!
Happy Blogging 🙂
Recent Comments